一、概论
三大机器学习类别:
- 监督学习:有标准答案的试错学习。
- 无监督学习:根据一定的假设寻找数据内部的结构,无监督学习是未来。
- 强化学习:延迟满足,根据结果来调整行为。和监督学习比,强化学习的反馈是不及时的。
监督学习:
- 分类
- 回归
无监督学习:
- 聚类
- 密度估计
用于执行分类、回归、聚类和密度估计的机器学习算法:
监督学习的用途:
- k-近邻算法
- 线性回归
- 朴素贝叶斯算法
- 局部加权线性回归
- 支持向量机
- Ridge回归
- 决策树
- Lasso最小回归系数估计
无监督学习的用途:
- K-均值
- 最大期望算法
- DBSCAN
- Parzen窗设计
算法选择:
如果想预测目标变量的值,选择监督学习算法。如目标变量是离散型,选择分类器算法;如果是连续型选择回归算法。
如果不想预测目标变量的值,可选择无监督学习算法。如果只想将数据划分为离散的组,使用聚类算法;如果还需要估计数据与每个分组的相似程度,则使用密度估计算法。
下图是sk-learn对算法选择的总结。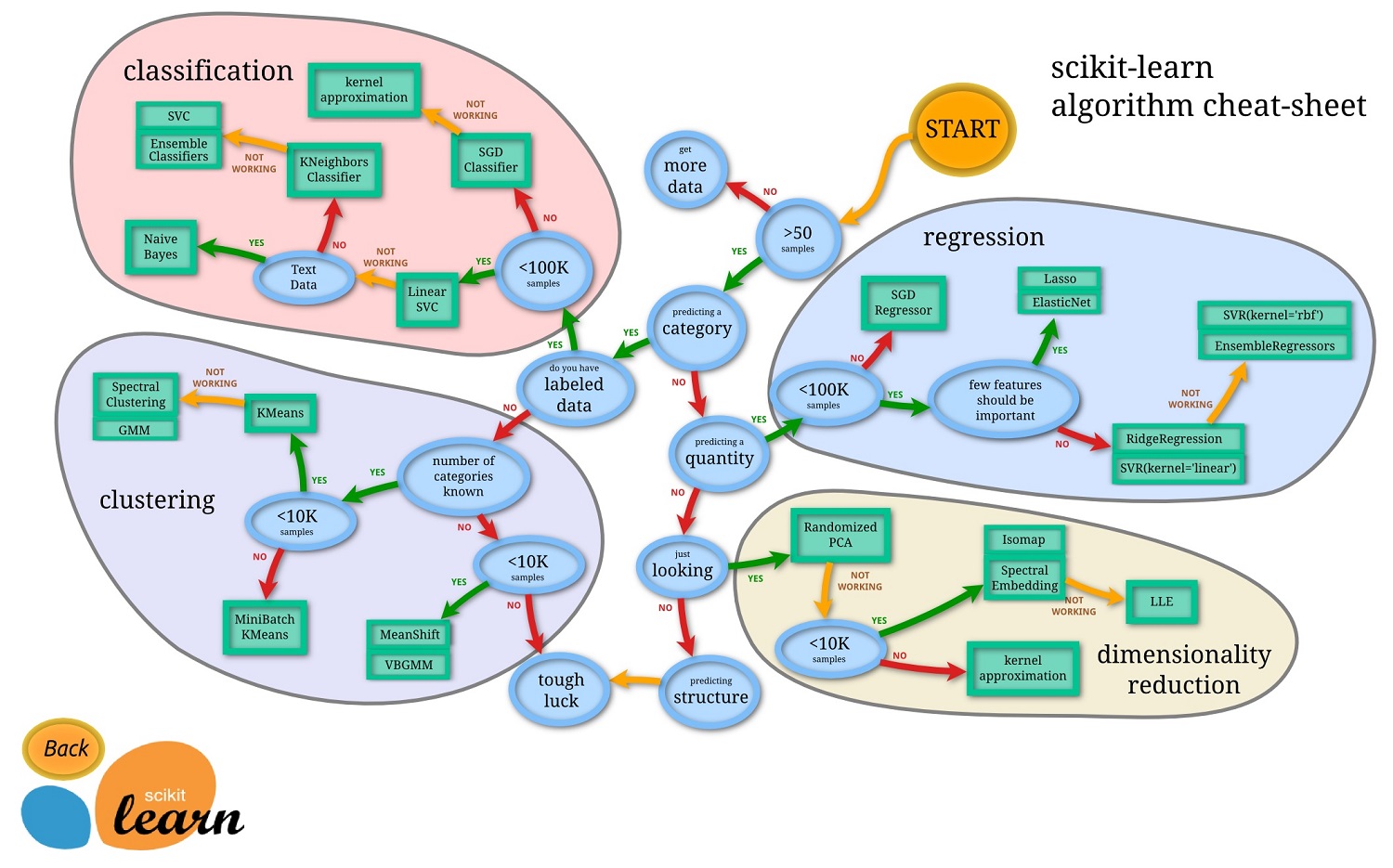
数据标注是第一生产力。
线性回归,根据特征,赋予特征的权重,计算cost代价,检验估算值和正确价格的偏离程度。
代价函数
怎么去寻找
过拟合,追求完美,会导致过拟合。允许一定的误差,增加数据量,将样本分成训练集和测试集,来避免过拟合。
欠拟合,误差太大,比如把树认为树叶。
生活永远是去找次有解,没有最优解
强化学习,马尔科夫决策树
Real trainging pineline
SL network classification (supervised learning)
RL network classification
Evaluation network regressioin
alphago的启示:人工智能的潜力是无限的,但人工智能发挥作用是有条件的:目标明确,规则明确,信息完全。但真实的世界和围棋不一样。
使用机器学习应用程序的步骤:
- 收集数据
- 准备输入数据
- 分析输入数据
- 训练算法
- 测试算法
- 使用算法
一般来说,大部分机器学习都要求:
线性代数:矩阵/张量乘法、求逆,奇异值分解/特征值分解,行列式,范数等
统计与概率:概率分布,独立性与贝叶斯,最大似然(MLE)和最大后验估计(MAP)等
优化:线性优化,非线性优化(凸优化/非凸优化)以及其衍生的求解方法如梯度下降、牛顿法、基因算法和模拟退火等
微积分:偏微分,链式法则,矩阵求导等
信息论、数值理论等
一般人如果想要把这些知识都补全再开始机器学习往往需要很长时间,容易半途而废。而且这些知识是工具不是目的,我们的目标又不是成为运筹学大师。建议在机器学习的过程中哪里不会补哪里,这样更有目的性且耗时更低。